
1. rank
2. dense_rank
3. nitle
4. listagg
5. lead
6. 누적데이터 출력함수
7. pivot과 unpivot
1. rank함수 - 순위를 출력하는 함수
rank() over (order by 컬럼명)
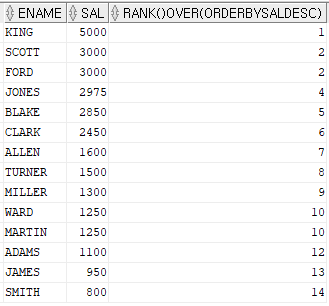
예제) 이름, 월급, 월급에 대한 순위를 출력하시오
select ename, sal, rank() over (order by sal desc)
from emp;a
2. dense_rank
rank함수와 비슷하지만 위의 쿼리의 결과의 경우 월급이 3000인 사람은 scott과 ford로 둘이다.
둘다 2순위로 나오고 그 밑에 jones는 4순위로 나온다 dense_rank를 사용하면 비는 숫자 없이 나온다.
예제) 이름, 월급, 월급에 대한 순위를 출력하는데 dense_rank를 사용하시오
select ename, sal, dense_rank() over (order by sal desc)
from emp;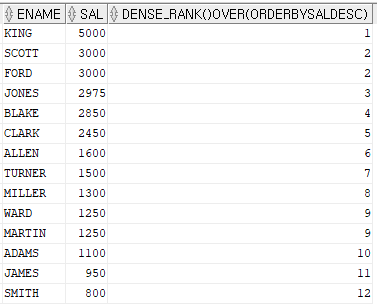
3. listagg - 결과를 가로로 출력하는 함수
listagg ( 출력할 컬럼명, ', ') within group by (order by 컬럼명)
-> 뒤에 within group by (order by 컬럼명) 은 안써도 무관하다.
select deptno, listagg(ename, ', ') within group (order by ename)
from emp
group by deptno;
4. ntile 함수 - 등급을 출력하는 함수
ntile(나눌 등급의 수)
예제) 이름, 입사일, 입사한 사원순으로 등급을 나누는데 5등급으로 나누시오
select ename, hiredate, ntile(5) over (order by hiredate asc)
from emp;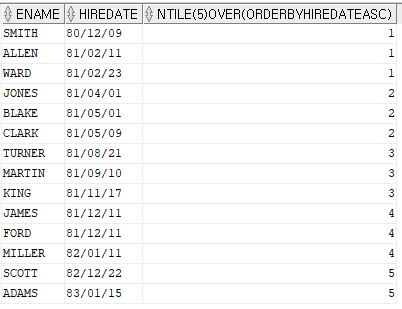
5. lag 함수 - 바로 전행을 출력하는 함수
select ename, sal, lag(sal, 1) over (order by sal asc)
from emp;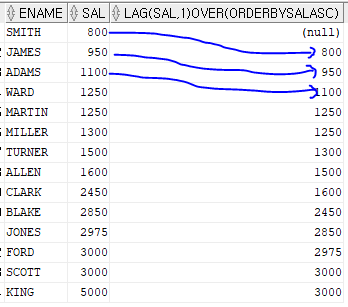
예제) 이름, 입사일, 바로전에 입사한 사원과의 간격일을 출력하시오
select ename, hiredate, lag(hiredate,1) over (order by hiredate asc) as 바로전입사,
hiredate-lag(hiredate, 1) over (order by hiredate asc) 간격
from emp;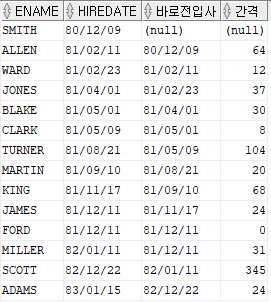
6. lead 함수 - 바로 다음행을 출력하는 함수
select ename, sal, lead(sal, 1) over (order by sal asc)
from emp;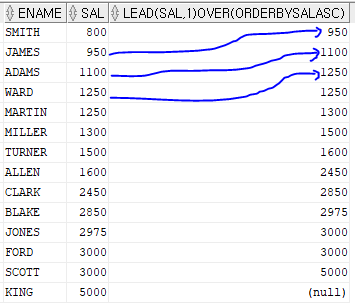
7. pivot과 unpivot
pivot - 로우(row)를 컬럼(column)으로 출력하는 함수
unpivot - 컬럼(column)을 로우(row)로 출력하는 함수
예제) 부서번호, 부서번호별 토탈 월급을 가로로 출력하시오
select *
from (
select deptno, sal
from emp
)
pivot (sum(sal) for deptno in (10,20,30));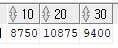
* pivot문은 pivot할 데이터를 알아야 사용이 가능하다.
->pivot 없이 출력하기
select deptno, sum(sal)
from emp
group by deptno;

*pivot문도 사용하긴 하지만 decode문으로 많이 쓴다.
select sum(decode (deptno,10,sal))as"10",
sum(decode (deptno,20,sal))as"20",
sum(decode (deptno,30,sal))as"30"
from emp;-> 위의 쿼리를 실행 해보면 pivot문을 사용한 것과 결과가 동일하게 출력된다.
8. 누적데이터 출력함수
누적 데이터 출력하는 방법
select ename, sal, sum(sal) over (order by sal rows
between unbounded preceding
and current row) 누적치
from emp;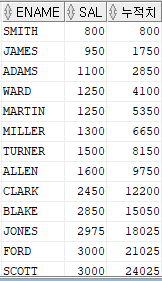
※ unbounded preceding : 제일 첫번째 행
unbounded following : 맨 마지막행
current row : 현재 행